Identity in necessary for communication, formal or informal. In other words, the concepts that are defined in our ontology are only useful and usable if I can distinguish one from another. This ability to distinguish one concept from all others we will refer to as establishing identity.
Our modeling approach is based on “standards” used in the World Wide Web as defined by the World Wide Web Consortium (W3C). Identity on the Web is established by a Universal Resource Identifier (URI). If two things have the same URI they are not two things—they are the same thing. Period. Note that the inverse is not true. Just because there are two URIs, it is not necessarily the case that there are two different things. In fact, it is not unusual for different modelers to create their own unique identifier for the same concept. There is, as we shall see, a way of stating that two URIs identify the same concept.
Fortunately, Web standards provide more than just a syntax for identifiers (URIs). They also provide the concept of an XML namespace. A namespace is a set of names and is itself identified by a URI. All the names in a namespace share the namespace’s URI and are distinguished from one another by a local name or fragment. The namespace URI is like a family surname and the local name is like a given name, except that in our case there cannot be duplication of given names. This means that names (local names) only need to be unique within the namespace. Again, by analogy, it’s fine to have a person named John in the Adams namespace and a person named John in the Kennedy namespace. The problem of establishing unique identifiers is not eliminated, but it is made much easier.
Extending our example to fit URI syntax, the URIs for our two namespaces might be:
Using the local name John, we can now construct the URIs for each person and include some other people too:
So far we have for each person listed 1) a URI establishing identity, and 2) a [local] name by which they are known in the namespace (family). URIs tend to not be very human-reader-friendly, so we introduce one more way of referring to something—the qualified name or qname. Suppose that we gave a nickname to each namespace. We’ll call the first adams and the second kennedy. This isn’t a valid global approach, but in a limited context, as long as this mapping from namespace URI to nick name is shared by all parties concerned and is unique, we could refer to persons by their qname:
It is an [almost] unbearable burden to have to create a globally unique identifier for everything. As humans, we don’t do it. (In fact, even when an identifier exists we will not necessarily use it. When’s the last time you used the VIN of your automobile in conversation?) Mostly we identify things by their relationship to other things that are easily identified. Fortunately, in the ontology language we use, we can do exactly that—identify things solely by their relationship to other things. As we’ll see a little later, such an unnamed concept is called a blank node or bnode.
People naturally categorize things. This is very beneficial in at least two ways. 1) It allows us to compress the enormous quantity of information that bombards us every day into higher-level representations. 2) It allows us to communicate much more parsimoniously. What people do subconsciously mathematicians have been formalizing for millennia as set theory. A set is a grouping of things, usually similar in some way we care about. In ontologies we often call this grouping or category or type a class.
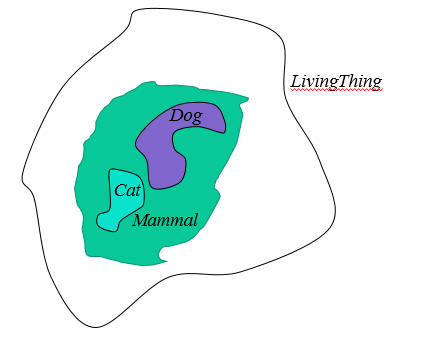
Sets, whether formal or informal, are useful in part because we can order them in hierarchies of classes, sub-classes, and super-classes. For example, we might define the class LivingThing and put in it all things that are alive. We might further define the class Mammal as those instances of LivingThing that are warm-blooded, have hair, and give milk to their offspring. We then say that Mammal is a sub-class of LivingThing. What we mean by this is that every instance of a Mammal is also an instance of a LivingThing. Similarly, Dog and Cat are sub-classes of Mammal, etc. Viewed as a Venn Diagram, the sub-class is entirely within the super-class as shown in Figure 1. It is helpful when creating sub-classes of a given class if they are distinct, meaning that no member of one sub-class is also a member of a sibling sub-class. The diagram in Figure 1 assumes that of Dog and Cat.
Figure 1: Venn Diagram of LivingThing, Mammal, Dog, Cat.
Partial ordering in class hierarchies is very powerful both in terms of compressing information and in terms of decompressing information to “infer” answers. Thus, if I am unfamiliar with the class Civet but you tell me that it is a Mammal about the size of a small Dog, you have in one sentence conveyed to me most what there is to know about Civets.
Inexperienced modelers often confuse class hierarchy relationships with other relationships, especially aggregation—when something is part of something else. There is a very simple rule that can be applied to clarify such confusion. ClassA is a sub-class of ClassB if and only if every instance of ClassA is also an instance of ClassB. Try this on, for example, the class Bicycle. Suppose that you are tempted to say that Frame is a type of Bicycle. Ask the question, is every instance of Frame also an instance of Bicycle? Obviously not, so the class-subclass relationship is NOT the right one.
The individual things that we group together in a class are instances or members of the class. In creating an ontology the question often arises as to when to make a concept a class and when to model it as an instance. A couple of considerations apply to this question. First, the principle of keeping things as simple as possible favors just creating an instance. This is especially attractive if there is really only one instance of the would-be class that is of concern. However, if there are multiple instances AND these instances differ in some way important to the purpose of the model, then the concept must be modeled as a class so that individual instances of the class can be given different properties and there by differentiated.
Generalizing over individual things to create classes and class hierarchies is not the only way in which people extract models from observations. We also create groupings of the characteristics of things and how things are related to other things and give these names. For example, we call how long something has existed its age. Or how strongly something interacts with the mass of the planet its weight. Or the relationship to a being that someone likes to be with as friend. Or the relationship of a person to their offspring as child.
There is a somewhat natural tendency to differentiate between the characteristics of some thing and how the thing is related to other things. The essence of this differentiation seems to be the existence with identity of the object of the statement. If the object is an individual, a thing with independent existence and identity, then we call it a relationship. However, if not then it is a characteristic. By this explanation friend is a relationship but age and weight are characteristics. In our ontology modeling languages, we call both relationships and characteristics properties. In our modeling languages, we call relationships object properties and characteristics data type properties.
In our ontology modeling languages, properties as well as individuals and classes, are first-class citizens. By this we mean that they can be defined independent of anything else. This is not true in many programming languages. For example, in object-oriented languages like Java, properties are represented as fields in a class and cannot exist outside of a class definition. This means that the class of things which can have the property is implicit in where the property is defined. However, with independent property definitions we can state explicitly what class(es) of things can have this property by specifying the property’s domain. We can further specify what type of values a property can have by specifying the property’s range. In our examples, we might say that the domain of age and weight is PhysicalThing while the domain of friend is Person. The range of age and weight might be specified (ignoring units for the moment) as numeric.
Implicit in our discussion of properties in the previous section is the idea of a directed graph. An instance of the domain class can have a property with a value drawn from the range. For example, If Jonathan and David are instances of the class Person, one might say Jonathan friend David. Or one might say Jonathan age 23. Each of these statements has a subject, a property, and a property value. There is an explicit order to the statement. Jonathan has an age, 23 does not have an age. Therefore statements of this kind are a set of edges of a directed graph. We say that an ontology of this type is a graph model.
Given a graph model, we can express patterns to query the model. Continuing our example, one possible pattern would be ? age 23, meaning, "who has age 23?" The question mark in the subject location indicates that we want to find all of the statements in our model that have any subject and the property age with value 23. By giving question marks names to create what we call "variables", we can tie multiple graph patterns together to create a more complex pattern. For example, ?p1 friend ?p2, ?p2 age 23 means find all possible instances in the model such that some instance (p1) has a friend (p2) who has age 23.
Graph query languages allow one to express complex queries over a graph model by specifying a set of graph patterns. Languages differ in how the variables are identified (some use the ?<name> syntax as in this example), what connective is used between the individual graph patterns (we arbitrarily used a comma in this example), etc. Graph query languages are powerful ways to extract information from our ontologies.